Droplet——一款轻量的Golang应用层框架
Droplet——一款轻量的Golang应用层框架⌗
如标题所描述的,Droplet 是一个 轻量 的 中间层框架,何为中间层呢? 通常来说,我们的程序(注意这里我们仅仅讨论程序的范围,而非作为一个系统,因此这里不设计如 LB、Gateway、Mesh等内容,因为它们都处于程序以外)按不同的职责可以分为不同的层次,而按照不同的设计风格,常见的如下:
- 三层架构:UIL(UserInterfaceLayer), BLL(BusinessLogicLayer), DAL(DataAccessLayer)
- DDD分层架构(参考ddd-oriented-microservice):ApplicationLayer,DomainLayer,InfrastructureLayer
- 洋葱架构(参考Onion Architecture ):Application, Infrastructure, ApplicationService, DomainService, DomainModel。
Tips
洋葱架构其实也是基于DDD的,它是DDD分层架构的升级版本。
但是今天我想用于解释中间层的架构并非以上的任何一种,它也源自于DDD的分层架构,不过我配合了六边形架构来说明它,分层图如下:
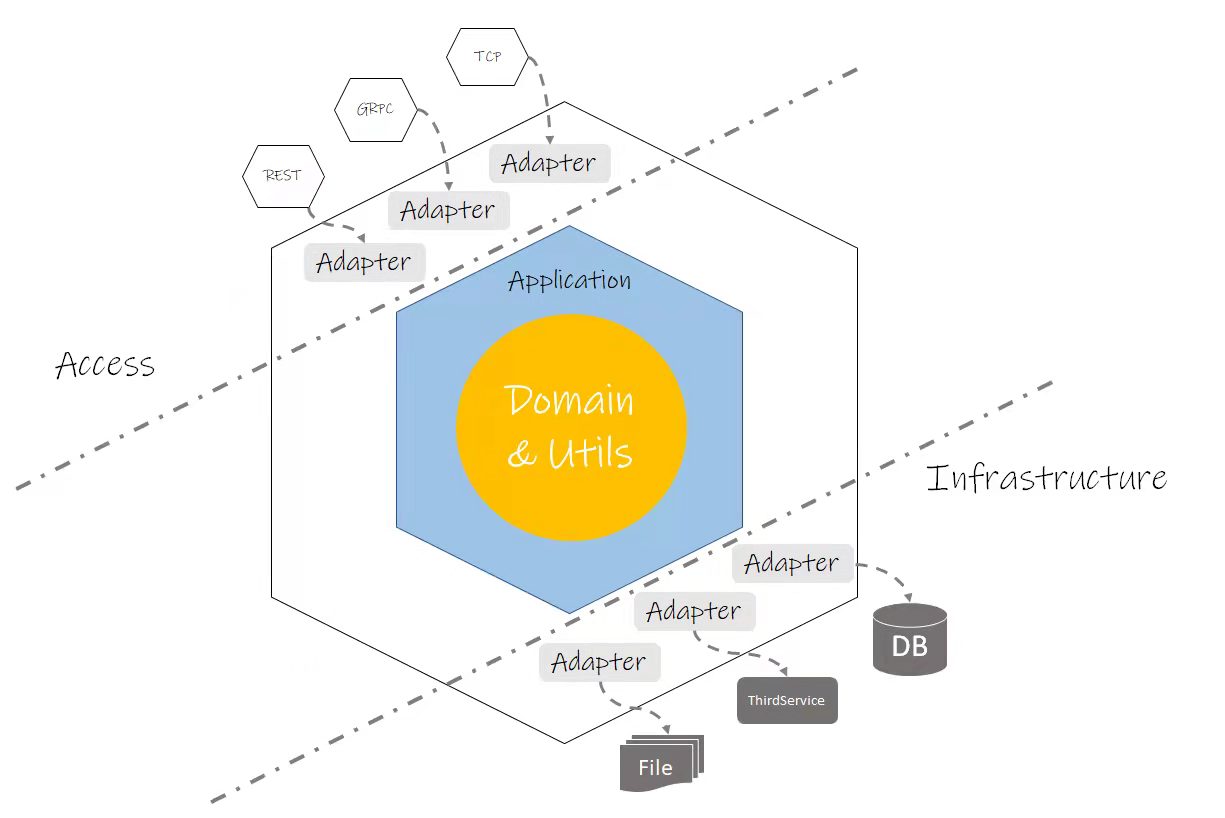
在六边形架构中有个规则:依赖只能是由外部指向内部。 因此从外层到最内层分别是:
| 分层 | 职责 |
|---|---|
| Access | 程序的接入层(在六边形架构中这被称为输入适配器),通常位于整个请求 or 任务的起点,它可能是某种Web框架,也可能是一些队列的消费框架等。 |
| Application | 程序应用层,包含了一些非业务的逻辑,如:业务逻辑的编排、参数绑定、校验、请求日志、链路上报、状态读取等等 |
| Domain & Utils | 在最中心的地方我放入了两个层次描述:Domain 与 Utils,这两个分层都应该是位于依赖的最底层,意味着他们不应该引用本项目的其他层次。Domain层主要包含核心的业务逻辑,而Utils则是一些程序任何地方都可能会引用的代码段,比如常量定义、数据结构和语法糖等等 |
| Infrastructure | 基础设施层(在六边形架构中这被称为输出适配器),程序所有需要对外进行信息交换 or 功能依赖时都会放置在这一层实现,通常来说这些功能都是被依赖的那部分,因此我们如果要满足依赖约束的话,这里必须要引入 DIP(Dependency inversion principle),即在Application、Domain中定义依赖,而 Infrastructure 来实现它们,这样保证了它们是可被替换的 |
六边形架构优点在于解耦程序中业务无关的部分,以保证它们都是可被替换与扩展的。
而 Droplet 就工作在 Application 层,它的核心能力只有一个:提供基于pipeline的请求/响应处理能力。
可能有人会疑问,几乎每个框架都会实现类似的能力,为什么我们需要 Droplet 呢?
别急,我们来看看这些框架自带的 pipeline/middleware 存在什么弊端。
根据上面的架构图我们可以知道诸如 gin、go-restful、fasthttp 之类的http框架都是工作在 Access 层,因此框架自带的 pipeline/middleware 存在以下两个弊端:
- 框架绑定: 这个很容易理解,这些机制只能工作于特定的框架下,如果切换框架则需要需要调整代码,除了中间件的代码外,我时常也会见到程序在 API Handler 中耦合了大量框架相关的代码,比如:读取参数(header, query, body等)、根据业务结果回写响应等,这些代码渗透到了业务程序中(有时它们甚至会比业务代码占用了更多的行数),这加大了业务开发同学的维护成本,同时也降低了程序的可扩展性。
一些相关的BadCase
想象一下:
- 你一直在使用 gin,但是有一天运营拿着数据找到你,说机器占用的成本太高了,而你发现只要切换到 fasthttp 就能为你带来更高的性能,但是从 gin -> fasthttp 你需要调整大量的 API handler 代码,这可太让人头疼了。
- API handler中充斥了诸如
param, ok := req.Query("param") / param, ok := req.Header.Get("param") / err := xxx.Bind(req, ¶m)之类的代码,这和业务毫无关系
- 没有请求/响应的结构化实体: 如果有开发过这些框架中间件的同学一定知道,大部分框架中间件的协议定义都是以
http.Request/httpResponse为主体的,这意味着如果不做任何前置处理,你只能通过字节数组来感知请求与响应这在部分场景都不太方便,比如:根据请求、响应的结构体是否具备某些特征(比如接口)来执行某些特定的业务通用逻辑;又或者想在中间件中融入一些自动化的参数校验逻辑,因为你没有一个具体的结构化对象;再或者你不想要在每一个 API handler 中去设置一个响应的 Wrapper(通常它类似于{code: 0, msg: "", data:{}}),想要在中间件去自动包装上它,也很难执行;最后就是——如果只依靠http.Request/httpResponse,你也难在中间件感知到其他参与者的处理状态,。
相信我说的这些问题,使用过的同学应该都有所感触,而这些问题并非难以解决,它们中的大部分基本都是可以通过自行建立一套约定来得以缓解(比如将这些信息都通过 context 去获取),而 Droplet 也是诞生于我在过往团队中去克服这些问题的实践之中,是一个相对可靠的实现。
工作原理⌗
带着上面提到的这些问题,我们来看看 Droplet 的工作原理是怎样的,如下图所示:

如我所说的那样,Droplet 的核心在于 提供基于pipeline的请求/响应处理能力,因此我们可以看见这个图中涉及的所有模块都是基于 pipleline,可以说 Droplet 的所有能力都是由其扩展而来。
这里我们先介绍下图中出现的几个中间件(Middleware,这是组成 pipepine 关键元素):
- HttpInfoInjector: 注入 http 相关的一些信息,如 requestid, http.Request 等
- RespReshape: 根据 handler 的响应结果来进行一些调整,包括:发生错误时设置上默认的错误码、错误信息;如果缺少响应 wrapper 时包装上配置好的 wrapper
- HttpInput: 如果你设置了 API 的输入参数类型,那么该中间件会自动根据 Content-Type、 struct tag 来读取对应的参数值,同时自动使用 validator 来检测参数错误
- TrafficLog: 如名字所示,如果你配置了响应的 logger,那么该中间件会执行日志记录。请注意该中间件工作在其他默认中间件的后面、你的handler之前,因此它统计的耗时是你业务函数的真正耗时,而不包含其他中间件的耗时时间,你可以考虑通过 网关 或 Mesh 来记录完整的接口耗时。
Tips
- Middleware 处理请求和响应顺序是相反的——即第一个处理请求的中间件它会是最后一个处理响应的。
- 框架工作在应用层的优势有两点:
- 与接入层框架解耦,保证绝项目代码可平滑 扩展/切换 其他接入层框架
- 能够获取到结构化的接口 输入参数 与 输出参数 你可以对其进行更具精细的切面操作
GetStart⌗
这里以
Gin为例,其他框架类似。
首先获取对应 wrapper 的 submodule:
go get github.com/shiningrush/droplet/wrapper/gin
// if you want to ensure the droplet is latest, you can get droplet
go get github.com/shiningrush/droplet
然后程序代码如下:
package main
import (
"reflect"
"github.com/gin-gonic/gin"
"github.com/shiningrush/droplet/core"
"github.com/shiningrush/droplet/wrapper"
ginwrap "github.com/shiningrush/droplet/wrapper/gin"
)
func main() {
r := gin.Default()
// 使用 wrapper 包装原始的 API
r.POST("/json_input/:id", ginwrap.Wraps(JsonInputDo, wrapper.InputType(reflect.TypeOf(&JsonInput{}))))
r.Run() // listen and serve on 0.0.0.0:8080 (for windows "localhost:8080")
}
type JsonInput struct {
// 从 path 读取, 并且为必须参数
ID string `auto_read:"id,path" json:"id" validate:"required"`
// 从 header 读取, 并且为必须参数
User string `auto_read:"user,header" json:"user" validate:"required"`
// 从 json unmarshal 后的ips字段读取
IPs []string `json:"ips"`
// 从 json unmarshal 后的 count 字段读取
Count int `json:"count"`
// 读取原始的 http body,接收参数类型必须为 []byte or io.ReadCloser
Body []byte `auto_read:"@body"`
}
func JsonInputDo(ctx core.Context) (interface{}, error) {
input := ctx.Input().(*JsonInput)
return input, nil
}
参数绑定⌗
如 Usage 一节中所展示的,我们可以通过 wrapper.InputType 选项来告诉 Droplet 是否期望自动化进行参数绑定,如果某些场景下你不需要从 Body 进行自动的参数绑定了,可以通过显式的选项来禁止它,如:
r.POST("/json_input/:id", ginwrap.Wraps(JsonInputDo, wrapper.InputType(reflect.TypeOf(&JsonInput{}), wrapper.DisableUnmarshalBody())))
参数绑定的Tag格式如下:
auto_read: ({key},{source}) or @body
其中值如下:
- key: 用于到各个来源中匹配对应值
- source: 可选值有 query, header, path, body(缺省默认)
- @body: 特殊的取值,意味着获取原生的body作为字段值,此时你的字段类型应该为 []byte or io.ReadCloser
同时 Droplet 会自动使用 validator 对入参进行校验,因此你可以使用其 tag 来辅助验证参数合法性。
响应整形⌗
通常来说API都会在响应的最外层进行一层包装,比如 Droplet 自带的 wrapper 如下所示:
{
"code": 0, // API 错误码
"message": "", // API 消息
"data": {}, // 响应数据
"request_id": "" // 请求ID
}
当然你可以完全去掉这个默认 Wrapper 或者 使用满足你们团队规范的 Wrapper(需要实现 data.HttpResponse 接口) 来替换它:
type NativeJsonResp struct {
data interface{}
}
func (n *NativeJsonResp) Set(code int, msg string, data interface{}) {
n.data = data
}
func (n *NativeJsonResp) SetReqID(reqId string) {
}
func (n *NativeJsonResp) MarshalJSON() ([]byte, error) {
return json.Marshal(n.data)
}
func main() {
...
droplet.Option.ResponseNewFunc = func() data.HttpResponse {
return &NativeJsonResp{}
}
...
}
对于另外一些并不需要 Wrapper 或者 你想要自行控制返回的内容时可以在 Handler 中使用一些实现了特定接口的返回值,如下所示:
func GetLoginQRCode(ctx droplet.Context) (interface{}, error) {
type makeQRCodeResp struct {
SceneID string `json:"scene_id"`
State int `json:"state"`
Url string `json:"url"`
}
var resp makeQRCodeResp
if err := goreq.Get(UrlMakeQRCode, goreq.SetHeader(fakeClientHeader()), goreq.JsonResp(&resp)).Do(); err != nil {
return nil, fmt.Errorf("get qrcode failed: %w", err)
}
return &data.RawResponse{
StatusCode: http.StatusOK,
Body: []byte(fmt.Sprintf(QRCodeBase, resp.SceneID, resp.SceneID, resp.Url)),
}, nil
}
类似的还有 data.FileResponse 、data.SpecCodeResponse,根据其名字你可以在需要的场景选择它们。
同时在整形过程中,为了业务研发不再需要关心错误处理,Droplet 会自动将 err != nil 的响应转化到 code 与 message 字段上。
如下图所示:
func ErrorAPI(ctx droplet.Context) (interface{}, error) {
return nil, errors.New("failed")
}
那么你将得到如下的响应:
{
"code": 10000,
"message": "failed"
}
当然,你可以使用 data.BaseError 来指定你想返回的错误码:
func ErrorAPI(ctx droplet.Context) (interface{}, error) {
return nil, data.BaseError{Code: 100, Message: "custom message"}
}
Tips
- 这些特定的响应其背后都是实现了某一类接口,如果有需要你也完全可以自行实现。
流量记录⌗
Droplet 自带了记录 API 出参与入参的能力,但是默认所有记录信息都会被抛弃,如果想要启用它,你需要实现 Droplet 的全局 Logger,如下所示:
import (
"github.com/shiningrush/droplet/log"
)
func main() {
...
// CustomLogger 需要实现 log.Interface
log.DefLogger = &CustomLogger{}
// droplet 默认只会记录 Path,Method,耗时等信息,如果你需要打印 API 的输入与输出,可以在全局选项中开启(在Wraps函数中也可指定)
droplet.Option.TrafficLogOpt = &middleware.TrafficLogOpt{
LogReq: true,
LogResp: true,
}
...
}
自定义中间件⌗
实现一个自定义中间件很简单,你只需要实现与 Hanler 类似的接口即可,下图是一个简单的中间件,它会用于检测输入参数是否需要 Quota 并执行相关逻辑:
type DemoMiddleware struct {
// 继承基本的middleware,里面有用于实现处理链路的公共逻辑
middleware.BaseMiddleware
}
func (mw *HttpInputMiddleware) Handle(ctx core.Context) error {
if ck, ok := ctx.Input().(QuotaChecker); !ok {
if err := ck.IsQuotaEnough(); err != nil {
return err
}
}
// 调用下一个中间件,有需要的话你也可以在响应返回后执行部分逻辑
return mw.Handle(ctx)
}
func main() {
// 如果你需要所有API都添加该中间件,可以在全局选项中将你的中间件编排
droplet.Option.Orchestrator = func(mws []core.Middleware) []core.Middleware {
return append(mws, &DemoMiddleware{})
}
...
// 在单个API上启用
r.POST("/json_input/:id", ginwrap.Wraps(APIHandler,
wrapper.Orchestrator(func(mws []core.Middleware) []core.Middleware {
return append(mws, &DemoMiddleware{})
})))
...
}
Tips
Q: 为什么使用 Orchestrator 这样的形式来配置中间件,而非通过 Priorty 之类的权重来实现中间件的编排,这样在未来可以做到通过配置文件来调整中间件
A: 主要出于几个考虑
- 考虑现代微服务的架构下,多数业务无关的通用能力都会下沉到网关以及Mesh,因此一个服务的切面不会太多,在通过这样的方式来配置,成本是可以接受的。
- 通过 Orchestrator 方式,用户还可以任意操作已添加的中间件,比如移除一些不必要的中间件,这是权重的方式无法做到的。
- 当然如果以后有需要,现在的设计并不妨碍我们支持基于权重的方式
小结⌗
正如文中所说,Droplet 的核心目标是 提供位于应用层的、pipeline 形式的请求处理能力,并以此为基础提供了一些开箱即用的中间件。 它对项目带来的收益总结为几点:
- 提供了框架无关的请求处理能力,这使得我们的服务更具韧性
- 在应用层我们可以接触到 已序列化后的接口输入 以及 尚未序列化的接口输出 ,这使得我们在离业务更近的地方进行切面操作,进而将更多的通用代码沉淀到切面而降低业务代码的复杂度,更聚焦业务逻辑。
希望 Droplet 能对你有所帮助与启发。