k8s笔记
k8s 笔记⌗
这里记录一些常用但容易忘记的内容。
存储相关⌗
ConfigMap 热更新⌗
更新configmap后:
- 使用该configmap的环境变量和命令行参数不会触发更新。
- 使用该configmap挂载的数据卷会触发更新。
- 如果使用子路径(Subpah)方式挂载的数据卷,将不会触发更新。
PV(PersistentVolume) 与 PVC(PersistentVolumeClaim)⌗
类似 Pod 与 Node 的关系,每个 PVC 可以与一个 PV 绑定。它们之间需要满足以下条件:
- 请求大小相同
StorageClass相同
但是与 Pod 的不同处在于:一个 PVC 只能与 PV 一一对应(因为要求资源大小相等)。
使用 PV 我们让一个 POD 的存储得以持久化,通常来说我们都会配合 StatefulSet 来使用。当然,你完全可以通过 PV 让一个 Deployment 持有状态,但 StatefulSet 会更适合有状态的场景。
同时 StatefulSet 中还提供了 VolumeClaimTemplates 这样的字段来方便自动创建 PVC,配合 动态PV 可以轻松驾驭持久存储的体系。
一些 Tips:
- 预先创建
PV再创建PVC绑定它们的这种方式被称为静态PV,在1.12出现了StorageClass来完成自动创建PV的过程,被称为动态PV。 StorageClass是一个CRD( 自定义资源 ), 它包含了如何访问数据源的一些细节,如参数,类型等等,为动态PV提供了支撑。在之前,这些信息都保存在PV中。StatefulSet删除时不会自动删除PVC,需要用户手动删除,这是为了让用户能够恢复数据。其他资源则不会,如Deployment。
杂项⌗
- client-go 中提供了很多有用的库:workerqueue(包含限速和延迟队列,多对多且并发安全), leaderelection, resourcelock(类似分布式锁)
- ServiceAccount 已弃用,ServiceAccountName 是最新项
- 每个 ServiceAccount 创建时都会自动生成一个 ServiceAccoutSecret,并且挂载到使用了 ServiceAccount 的 Pod 中
- 可以使用以下命令查看容器中的网络
docker inspect -f {{.State.Pid}} 容器id # 获取容器的pid
nsenter -n -t pid # 进入容器网络空间
简写为
nsenter -n -t $(docker inspect -f {{.State.Pid}} dockerid)
- ssh 在登录过程中会清理环境,导致 k8s 设置的环境变量都被删除,解决方案可以参考
- yaml对于分段内容有几个方法(>, |, +, -),可以参考 这里
网络模型⌗
k8s 对网络提出了三个基本要求
- pods on a node can communicate with all pods on all nodes without NAT ( 节点上的 POD 不需要通过 NAT 就可以与其他任意节点的 POD 通信 )
- agents on a node (e.g. system daemons, kubelet) can communicate with all pods on that node (节点上的代理程序可以与该节点上的任意 POD 通信 )
下面的这个要求仅针对支持 HostNetwork 模式的平台,如 linux
- pods in the host network of a node can communicate with all pods on all nodes without NAT ( 节点上的 hostnetwork POD 不需要通过 NAT 就可以与其他任意节点的 POD 通信 )
实现了这些要求的技术方案有很多,可以参考 集群网络系统,这里列举几个比较知名的开源方案:
- Flannel
- Calico
各大云厂商也都实现这些网络要求以提供 k8s 集群的网络资源需求,由于云厂商在提供容器服务之前基本都有了自己的虚拟化技术而且基本都类似,所以他们都是基于各自的 VPC 网络模型来实现 k8s 的网络方案,比如:
- Google: Google Compute Engine (GCE), 详细情况未知
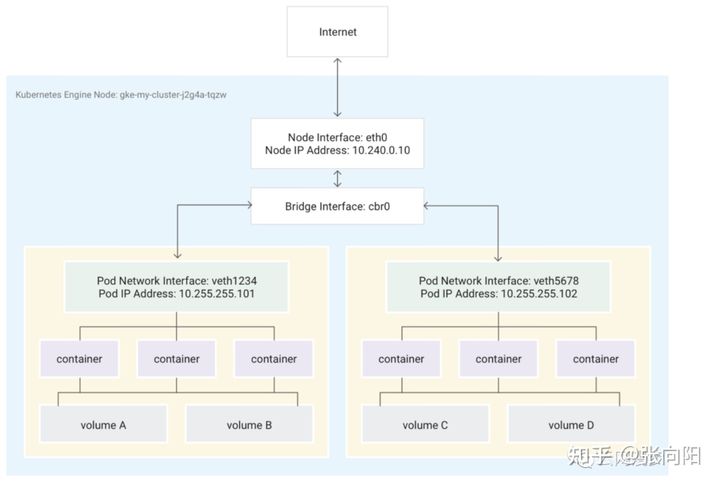
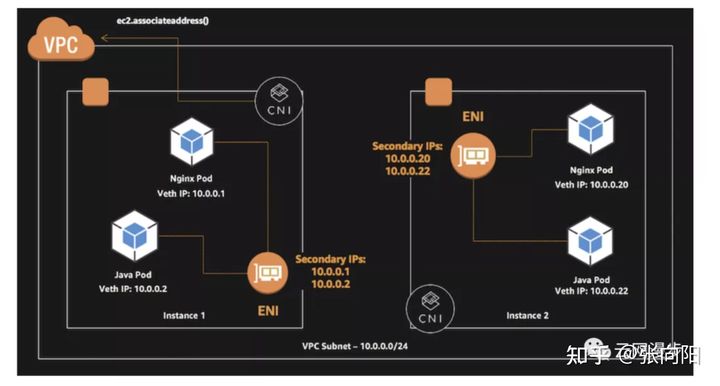
- AWS: AWS VPC CNI, 类似 Tencent VPC CNI
- Azure: Azure CNI, 详细情况未知
- Aliyun: Terway,类似 Tencent VPC CNI,兼容 Flannel
- Tencent:
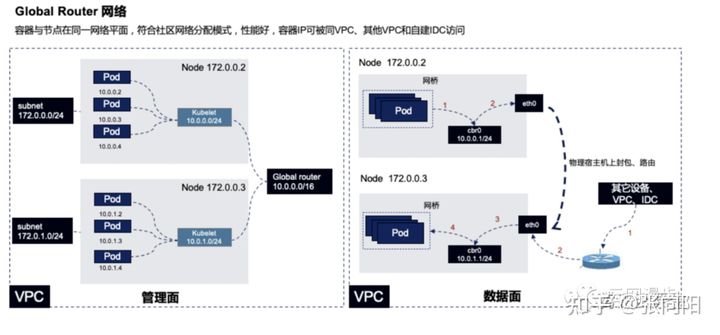
- Global Router: 使用 Overay 的技术建立的容器网路,母机 和 POD 网络互通,但是由于 Overlay 建立在 VPC 下,因此容器不能访问到不同 VPC 下的 POD。
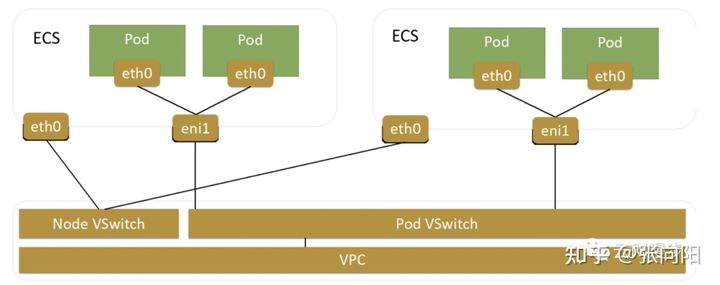
- VPC CNI: POD 和 母机 在一个网络平面,这个模式下 POD 和 母机以及 不同 VPC 下的母机都是互通的。
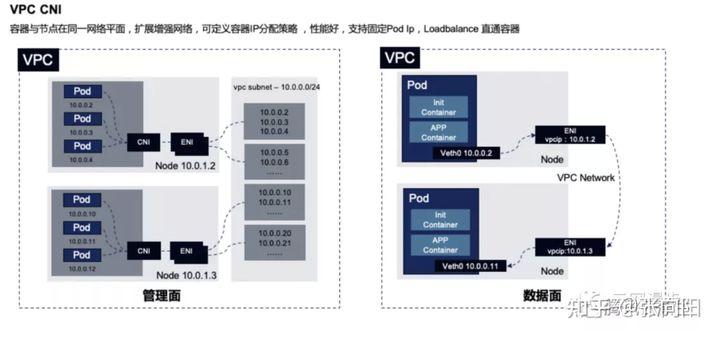
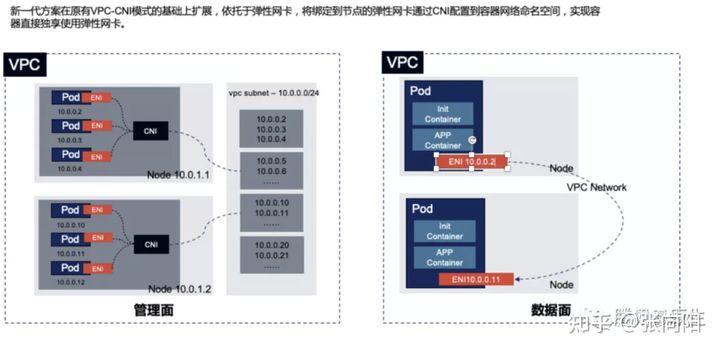
- VPC CNI 独立网卡模式: VPC CNI 母机上的 POD 都共用母机的 ENI,新一代的 VPC-CNI 直接将弹性网卡绑定到了 POD 网络命名空间,让其独享 ENi,在实践过程中来看,这个模式提高了网络稳定性,老模型在大包量的情况会出现丢包。
- Global Router: 使用 Overay 的技术建立的容器网路,母机 和 POD 网络互通,但是由于 Overlay 建立在 VPC 下,因此容器不能访问到不同 VPC 下的 POD。
NAT 相关⌗
k8s 当你使用 iptables 模式时,默认发往集群内的请求(比如 ClusterIP, POD)都不会进行 NAT,其他都会进行 NAT,但是当你请求集群外的地址且你的容器分配了独立可访问的IP时,你肯定不希望对方望看到的是你的母机IP,所以需要 ip-masq-agent 插件来帮助调整 NAT 的规则, 这个agent的工作原理就是利用 daemonset 部署到每个母机,同时调整母机上的 iptables 规则,值得一提的是现在很多集群的节点组件也会使用daemonset来部署,比如kube-proxy。
具体工作原理还可以参考 IPVS从入门到精通kube-proxy实现原理。
DNS解析⌗
FQDN(Fully Qualified Domain Name) 代表完全限定域名,在进行域名解析时将不会在后面追加顶级域名,PQDN( Partially Qualified Domain Name ) 部分限定域名,可以根据场景在后方追加顶级域名。
最明显的区别在于 FQDN 后跟一个 ., 如 www.baidu.com.
- 解析域名时,遵从
/etc/resolve.conf指定的参数,nameserver指代下一级查询的 dns 服务器,search指定在域名为 PQDN 时,尝试追加的基本域名 - k8s 在网络容器初始化时会根据 yaml 的内容来决定如何初始化 pod 的内容,参考 Pod 与 Service 的 DNS
- 在普通 linux 的
resolve.conf配置search后,如果请求域名中没有.那么认为是主机名,优先追加search的域名去查找,最后才查找主机名,比如host,如果含有点,且大于options.ndots:n当中配置的数量n,则认为是 FQDN 优先查找自身 如host.name,可以通过host -a命令查看解析域名的过程
CPU 管理策略⌗
k8s 在 linux 上管理容器CPU资源的策略有两种:
- CFS(Completely Fair Scheduler):使用CFS调度器控制CPU能够使用的额度
- CPUSet: 控制容器能够使用的CPU核
这两种策略通常会结合起来一起生效,比如设置某容器的CFS 的 quota 和 period 比值为 2核,但是 cpu set只绑定了 1 号核,那么容器能够使用的最大CPU也只有 1 核,反之也如此。 k8s 简单来说,当 limit = request 且 cpu管理策略为 static 时会为容器绑定专用核,其他情况会绑定共享CPU核。 详细内容可以查看控制节点上的 CPU 管理策略
这里需要注意的是cpuset不等于cpu亲和性,cpu亲和性一般使用
sched_setaffinity(2)来绑定,其指定的cpu必须属于cpuset。
k8s 的回收策略⌗
这里涉及到两个方向:
- 已经执行完的历史POD数据需要从ETCD中清理,此部分内容的相关配置在 scheduler 中
- 已经执行完的历史POD数据需要从母机上清理,包括容器记录和磁盘占用,这部分内容在 kubelet 中配置,可以参考 容器镜像的垃圾收集
第一点会影响集群的 APIServer 的性能,进而影响到整个集群,第二点如果不设置的话,有可能会导致母机磁盘写满,进而导致母机 NotReady。通常 kubelet 会在母机磁盘到达一定阈值(默认85%)后自动清理不使用的镜像,但是不会清理历史容器,所以也需要关注全局保留的旧容器数量,默认不限制。
健康检查⌗
在 k8s 中容器健康检查分为 两类:
- 存活探测( liveness probe )
- 就绪探测( readyness probe )
这两者的配置都一样,但是产生的结果不同:
- 存活探测:初始状态为满足,防止初始化时直接重启容器,探测失败直接重启容器。
- 就绪探测:初始状态为不满足,防止容器尚未就绪就将流量转发到 pod 中,探测失败会从 Endpoint 中移除。
从上面的角度来考虑,配置健康检查的最佳实践:
- 将存活探测后置于第一轮就绪探测来执行,防止第一轮就绪检查尚未成功时就重启容器
- 就绪探测比存活探测更密集,可以及时发现应用阻塞的情况,再配合存活探测来重启容器
原地重启⌗
优雅退出⌗
k8s 结束一个 pod 时会首先发送一个 TERM 信号 ( 可以在 Dockerfile 中使用 STOPSIGNAL 关键字指定退出信号 )给 POD 的所有容器,在等待 terminationGracePeriodSeconds 所指定的秒数后如果有容器尚未退出,那么给它们发送 KILL 信号。
这个流程需要注意:
- 你的容器启动命令是否启用使用脚本来启动程序,如果是,那么要注意 bash or sh 作为一号进程起来时并不会转发信号给自己的子进程,所以需要你显式处理。这里处理的手段分两种:
- 使用
exec来启动,这样命令会直接替换 shell 成为一号进程 - 使用 tini,它可以解决信号转发与回收僵尸进程的问题
- 使用
- 僵尸进程,如果你的程序会像 Jekins 一样执行一些用户脚本,从而产生一些不可控的僵尸进程,那么建议使用 tini
平滑更新⌗
平滑更新在 k8s 中其实是相对容易实现的,只要注意以下几点:
- 如果使用了集群外的服务发现机制,比如 consul, zookeeper,这里分情况:
- 如果没有做缓存,那么只需要考虑做好应用的优雅退出即可
- 如果做了缓存,那么需要做好端点的健康检查,防止重用旧的端点
- 如果使用
Service来做服务发现,要注意 endpoint 和 kube-proxy 都是异步的,所以保险的方法是使用preStop的生命周期钩子来等待更新
lifecycle:
preStop:
exec:
command: ["/bin/sleep", "15"]
terminationGracePeriodSeconds: 30
- 如果使用长连接,请注意在 k8s 1.14 版本以前会存在问题,因为 kube-proxy 会直接删除老规则,导致旧的连接收发包时会直接被丢弃,而在新版本中添加关于 Service 的优雅退出:
- 首先将老的规则权重更新为 0,这样新建立的连接 (connect) 并不会使用它
- 老的连接进行收发包时会正常进行
- pod 被销毁后,也会剔除老规则
- 应用的优雅退出不应该在接收到 SIGTERM 信号立即关闭监听端口,而应该先进行收尾工作:处理当前请求,关闭持有的长连接、Worker等,最后再关闭监听端口,以最大限度容忍由于某些异常原因依然抵达了该服务的请求。
这里还需要注意下 conn_reuse_mode 这个参数,如果 kube-proxy 工作在 ipvs 模式下会自动设置 conn_reuse_mode=0,很可能因为重用端口而导致以前的连接得不到释放(大量短连接的情况)
参考:ipvs模式的conn_reuse_mode问题, kube-proxy ipvs conn_reuse_mode setting causes errors with high load from single client
以一个 pod 的创建来观察 k8s 的组件协作⌗
一个 POD 要跑起来会经历以下流程
- 请求 k8s APIServer,将资源文件添加到集群,这里会涉及到 kubeConfig 的 认证,授权,以及准入控制(webhook 在这里生效,分为准入 webhook 以及修改的webhook)
- 当资源被 APIServer 接纳并写入etcd后,
Scheduler将会 Watch 到新的资源的产生,并尝试将 Pod 调度到Node上,这里调度涉及几个过程:- 预选:将会根据 Pod 的所需资源(包括计算资源、自定义资源、数据卷等等)、NodeName、NodeSelector、Node亲和性和容忍度,以及Node的健康状态,筛选出一批可容纳Pod的Node,这些过程都分布在不同调度策略中
- 优选:对上个过程中的Node进行打分,打分维度包括:节点的空闲资源,节点的POD数,Pod的亲和性和容忍度等,从中选出得分最高的节点,对节点和Pod进行绑定
- 当节点的 kubelet watch到有pod与自己进行了绑定则开始创建Pod,流程如下:
- 通过 CNI 创建网络空间,通过 CRI 创建 Sandbox,相继启动 Init容器与业务容器,再根据其需求判断是否需要使用 CSI 挂载数据卷,最近再进行健康检查与就绪检查。
至此整个 pod 则被拉起,这里值得一提的有几个点:
- CRI 创建 Sandbox 的流程在不同CRI下是不同的,比如 runC 体系下,会拉起 pause 容器,然后业务容器共享 pause 容器的网络命名空间,在kata下则会直接拉起一个虚拟机,其他容器则以进程方式共享这个虚拟机。
- docker 并没有实现 CRI 规范,因此为了支持 docker,k8s 维护了 dockershim 来作为转换组件,docker背后其实跑的也是 containerd,而containerd 可以选择 kata 与 runC 两个运行时,两者都符合 OCI(Open Container Initiative) 规范,此外 containerd 是实现了 CRI 规范的,只是由于历史原因,导致在很长一段时间 kubelet 支持的都是 docker 而不是 containerd,新版的 kubelet 已经弃用了 docker 而直接使用 containerd 方案了。
containerd命令行工具参考:
- ctr: containerd的官方工具,注意k8s的容器都在 k8s.io namespace下
- crictl: k8s为container 出的,和docker类似,但是可以直接查看pod
Strategic Merge Patch⌗
k8s 为了完善 json patch 的一些问题,提出了 Strategic Merge Patch,正常它的逻辑是有则覆盖,无则追加,同时还可以通过 yaml 的声明来控制行为,同时它使用一些特殊的指令来完成特别的操作,参考 Strategic Merge Patch
Server-Side Apply⌗
服务端应用主要用于解决以下问题:
- 当client直接提交资源时感知不到服务端的资源已经被修改,导致其他人的修改被覆盖
- 服务端还有一些hook的变更是client端感知不到的
在没有服务端应用之前,客户端提交的逻辑是,获取目标配置,计算 Diff 写入 last-applied-configuration annotation 中,下次提交时直接使用这个字段进行计算,然后将 Diff Patch到 APIserver。
这个操作还带来了另一个问题:如果某个资源的描述文件很大,会超过 k8s 的 annotation 只有 262144 字节的限制。
因此 k8s 在 1.18 中带来了服务端应用,详细查看:Server-Side Apply
BreakDownSSA
要注意SSA也带来了一些问题:
- 对于提交的yaml没有覆盖到的部分,只会采取 patch 的方式,而不是全集覆盖,这对于某些场景来说可能会是不好的行为
如何查看容器的文件⌗
参考:https://blog.px.dev/container-filesystems/
渐进式部署⌗
默认的k8s只支持 Recreate 和 Rolliupdate,其实在业务场景来说是不太够的,其他的发布策略还有:
- 蓝绿
- 灰度
为了支持这些东西,很多大厂都是基于 k8s 包装了更上层的概念来实现服务的发布部署,而社区目前有两个热度比较高的项目来支持这些功能:
- flagger: 属于 fluxcd 项目,和 argoproj 这个组织一样,都是以云原生的方式去推进工具的发展,fluxcd 项目主要聚焦在持续成与部署上。
- argo-rollouts: 上面已经介绍过了,这两个项目和组织的目的都高度相似。
简单来看,flagger支持更多的流量治理工具,而 argo-rollouts 可以很好的和它的CD项目结合。工作原理上没有太大区别,两者都需要使用各自的CRD来替换原生Deployment。